DRP – Disaster Recovery Plan
In Brief
The purpose of a Disaster Recovery Plan (DRP) is to plan for the timely re-establishment of an IT infrastructure. It aims to enable the operational recovery of services in the event of a disaster.
A disaster recovery plan differs from a business continuity plan.
- A disaster recovery plan is characterised by its technical approach to restoration following an IT disaster.
- A business continuity plan is a generic and strategic document, which plans and details the types of actions for managing a disaster or a serious incident.
A disaster recovery plan must allow a switchover to an ‘alternative’ IT infrastructure dedicated to the survival of the business or activity.
Disaster recovery plans are designed and updated according to business needs.
RTO and RPO
Any DRP must be based on the following two concepts:
RTO: Return Time on Objective – RTO
RPO: Recovery Point Objective – RPO
Any entity wishing to develop a disaster recovery plan will initially need to define security goals based on these basic needs (see Risk Management).
RTO
The RTO defines the maximum acceptable time during which an IT resource may be down due to a disaster.
This downtime takes account of:
- The time required to detect the incident,
- The time required to decide whether to launch the recovery procedure,
- The time required to implement the disaster recovery plan,
- Network configuration,
- Data restoration,
- Quality control and service-level control (in degraded or fully functional mode).
RPO
The RPO defines the maximum amount of data that can be lost as a result of a computer disaster. This value is the difference between the last backup and the incident. It is expressed in most cases in minutes / hours.
Incident Diagram
The diagram below shows service-level changes according to the incident. It aims to model the concepts of RPO and RTO to show how they differ, but also how they are complementary.
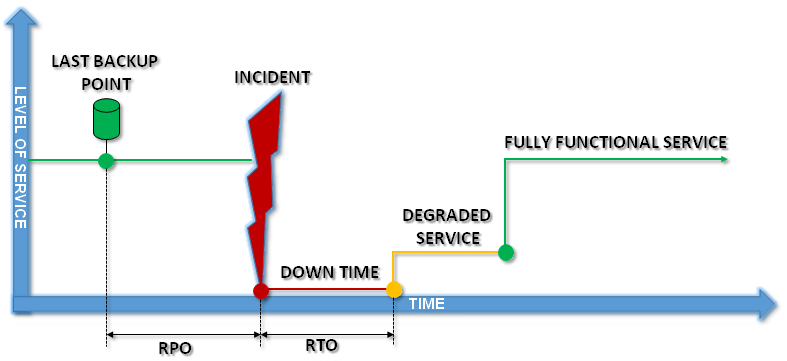
Depending on the size of the disaster, a recovery plan must be able to take account of many recovery scenarios, ranging from simple actions to complex mechanisms.
In concrete terms, a company is exposed to numerous daily risks, which may lead to a disaster and justify the activation of a recovery plan.
Examples:
- A viral infection requiring a system restore,
- A hardware failure requiring the replacement of the defective elements,
- The destruction of files requiring the activation of a means of restoration,
- A natural disaster or accident justifying the activation of a backup computer site.
The above examples are variable in terms of the RPO and RTO concepts and demonstrate that a backup plan must be based on different technologies to respond to a multitude of disasters.
- Backups,
- Replacement hardware,
- Redundant computer resources with high availability,
- Backup site.
Overall, the implementation of a recovery plan is based on 12 key points.
12 Key Points for a Successful DRP
1. Inventory of IT Assets
Any asset that is part of the infrastructure’s IT system must be clearly identified and listed in a Configuration Management DataBase (CMDB).
- Connectivity and network: routers, switches, racks, etc.
- Shared hardware: servers, storage, printers, etc.
- Individual hardware: workstations, laptop computers, smartphones, etc.
- Server rooms, backup storage rooms, etc.
- …
The database must be kept up to date. We recommend adding a field that allows you to enter the date on which the equipment was first used to identify wear and tear and obsolescence.
2. Inventory and Mapping of Data and Applications
Each database and each application must be clearly identified in a database, shared with the IT assets database, to show the relationships between physical assets and logical assets.
At any given time, this database should allow you to answer the following question: ‘Which application is hosted on which server?’ At this stage, it is just as important to map the IT infrastructure to model the links between server rooms and servers – storage – flows – applications – databases.
3. Classification
The classification of assets entails a process involving business line managers (trade, accounting, etc.), the IT manager, and a member of the management board.
The aim is to determine which applications are necessary for the optimal running of the ‘company’. We recommend using the following value scale:
-
Vital application:
- The permanent loss of this application and the associated data would force the company to cease trading or would cause very serious difficulties.
- The temporary loss of this application and the associated data would result in a significant operating loss.
-
Critical application:
- The permanent loss of this application and the associated data would result in a short- or long-term loss of service and part of the workforce would have to be laid off.
- The temporary loss of this application and the associated data would result in a minor operating loss.
-
Standard application:
- The permanent loss of this application and the associated data would have a negligible impact on the company’s activity.
- The temporary loss of this application and the associated data is virtually insignificant.
Once each application has been classified, the IT manager must attribute the same classification level to each IT resource. In the case of shared resources, the most critical classification will always take priority.
Thanks to this classification, the IT manager can prepare the disaster recovery plan following the business priorities.
4. Analysis of Vital Business-related Needs / Prioritisation / Risks
Based on the inventories and asset classifications, the IT manager draws up a document establishing the rules of priority for restarting services.
This document must be approved by a member of the management board.
For its part, the board of directors must appoint an expert to handle any risks to which the ‘company’ is exposed (risk analysis).
The success criteria for stage 4 is exhaustive knowledge of the company’s IT environment and the risks to which it is exposed.
5. Establishing RPO/RTO Thresholds
Once the previous step has been validated, the IT manager, along with the business line managers and a member of the management board, all meet to determine the RPOs and RTOs.
This is an important stage because they look at the IT system’s ability to resolve a disaster in accordance with the company’s needs and risks.
Expected objectives:
- The business line managers and the member of the management board must:
- Set the maximum acceptable Return Time on Objective (RTO) by application, assuming an incident involving a single application.
- Set the maximum acceptable Return Time on Objective (RTO) assuming a disaster affecting the whole company. At this point, the use of downgraded mode should also be discussed.
- Set the maximum acceptable Recovery Point Objective (RPO)
- The IT manager must:
- Compare their view to that of the business to provide better explanations and find a compromise about disaster recovery capabilities.
- Negotiate with the management board to obtain the technical and financial resources to meet the business’s requirements.
6. Study of Technical and Financial Solutions
Based on the results of the negotiations in stage 5, the IT manager must consider and suggest technical solutions that meet the business’s requirements.
The IT manager’s work must focus on two issues:
- RPO-dedicated solutions,
- RTO-dedicated solutions.
A number of solutions currently exist to meet the business’s requirements, but the costs can vary significantly. The lower the RTO/RPO thresholds, the higher the costs.
7. Approval
Once the IT manager has finished looking into technical feasibility, they present a report to the members of the management board containing the choices that best meet the business’s requirements and the financial and technical limitations.
Insofar as investments must be made to develop or maintain the disaster recovery plan, this need must be mentioned in the report.
Once this stage has been approved, the IT manager implements the technical solutions specific to the disaster recovery plan.
8. Implementation
Depending on the budget, resources and objectives, the IT manager initiates the implementation of the technical solutions, considering the deadlines set by the management board members. A schedule providing the deadlines must have received prior approval from the management board and IT manager.
9. Drafting of the Procedures
Once all of the technical solutions are up and running, those in charge of their maintenance must write up technical implementation procedures. These must be tested by a third party.
For security reasons, these procedures must not be stored in the same physical environment. They must be safeguarded against any modifications or alterations and protected in such a way that they can only be accessed by those who need to read them.
10. Drafting of the DRP and Activation Conditions
The IT manager, who is the de facto manager of the disaster recovery plan maintenance, must ensure that the technical procedures are protected, available, and up to date.
At the end of the process, they start drafting the disaster recovery plan based on various scenarios and taking care to include, for each situation, the activation conditions and the related technical processes.
In concrete terms, a scenario stages a risk to which the ‘company’ has been exposed and presents the solution to resolve the situation under the RPOs and RTOs.
A scenario must be put together ‘simply’. Here are two examples of a scenario:
Scenario 1: Exploitation of a Wi-Fi weakness by a malicious entity =>Risk analysis has previously detected a vulnerability in the Wi-Fi infrastructure that gives access to the internal network. The WPA key has not been changed for two years, the ‘password’ is weak and it is known by all staff members, including ‘person’ who no longer work for the company.
General theme: A hacker is hired by competitors to corrupt customer data.
The attack:
A hacker, motivated by financial gain, has the IT resources and expert knowledge required to exploit the technical vulnerabilities of the IT network. More specifically, they take advantage of the poorly protected Wi-Fi connection and corrupt the server on which the customers’ financial data is hosted, affecting the integrity of the data. They voluntarily change the customers’ financial information (debits/credits/pending transactions).
Key ingredients in this scenario:
- Sources of the threat: A competitor uses an underhand tactic to corrupt their rival’s IT systems.
- Threat: A hacker breaks into the network via a Wi-Fi connection to corrupt data. The hacker has the means and skills.
- Vulnerabilities exploited: Poorly protected Wi-Fi (weak and widely-known WPA key).
- IT system affected: Network + server.
- End elements affected: Customers’ financial data (Debits and Credits).
- Hacker’s desired outcome: Cause a loss of integrity.
- Potential impact on the organisation: Financial loss – Loss of customer confidence – Publicly discredited.
Elements to test:
- Can we detect such an attack?
- As it happens?
- Afterwards, by analysing the logs?
- Only after a customer notices an inconsistency?
- Can we meet the RTO?
-
Can we meet the RPO? Countermeasures / technical solutions to be tested:
- Sensitive data and network surveillance system.
Is an alert generated in the event of:
- use of the Wi-Fi outside of normal working hours,
- consultation of customer data outside of normal working hours, etc.
- All means of restoration enabling the recovery of data by the RPO.
- …
Scenario 2: Major fire in the server room => The risk analysis has previously detected several vulnerabilities in the room containing the servers that host the company’s vital data. There is no smoke detector, no automatic fire extinguishing system and the backup system is hosted in the same room as the servers.
General theme: A short circuit causes the total destruction of the server room.
The incident:
The company director has decided to start electrical renovation works. On Friday evening, a tradesman working on the electrical board in the server room forgets to connect the circuit breakers. In the early hours of Saturday morning, overheating caused by a faulty contact causes a fire that destroys all of the IT equipment. To make things worse, the backup systems are kept in the same server room. However, a copy of the backups is placed in a safe in an adjoining building on a monthly basis.
Key ingredients in this scenario:
- Source of the problem: A fire
- Threat: Tradesman’s negligence
- Vulnerabilities: No smoke detection or fire extinguishing system
- IT system affected: Network + server + backup systems
- Immediate consequence: Loss of availability
- Potential impact on the organisation: Operational loss – financial loss
Elements to test:
Using the backup stored in the safe in the adjoining building:
- Can we meet the RTO?
- Can we meet the RPO?
Countermeasures / technical solutions to be tested:
- To restart IT services, are we able to:
- Use a temporary or replacement server room?
- Are Human Resources available and are they capable of reconstructing the infrastructure?
- …
- Is the supplier able to meet the terms of the SLA (if there is one) for the delivery of replacement equipment?
- …
11. Tests
The disaster recovery plan must be tested regularly. Using the document describing the different scenarios, the IT manager creates an incident scenario to test the technological and organisational capabilities of business recovery.
A report must be written at the end of each exercise. This report is sent to the management board and details both the positive and negative points of the disaster recovery test. In conclusion, the IT manager suggests improvements or recommendations if the RPO and RTO cannot be met.
12. DRP and Procedure Updates
The IT manager is responsible for ensuring that the disaster recovery plan and procedures are up to date. In the event of a major change to the IT infrastructure, the twelve key points cycle needs to be restarted.